記者鄧天心/綜合報導
在剛結束的Google I/O大會上,最讓創作者關注的焦點無疑是全新發表的「Gemini Omni」,根據Google官方釋出的技術白皮書與實際操作演示,這款模型與過去單純「輸入文字、輸出影片」的生成式AI體驗上不太一樣。
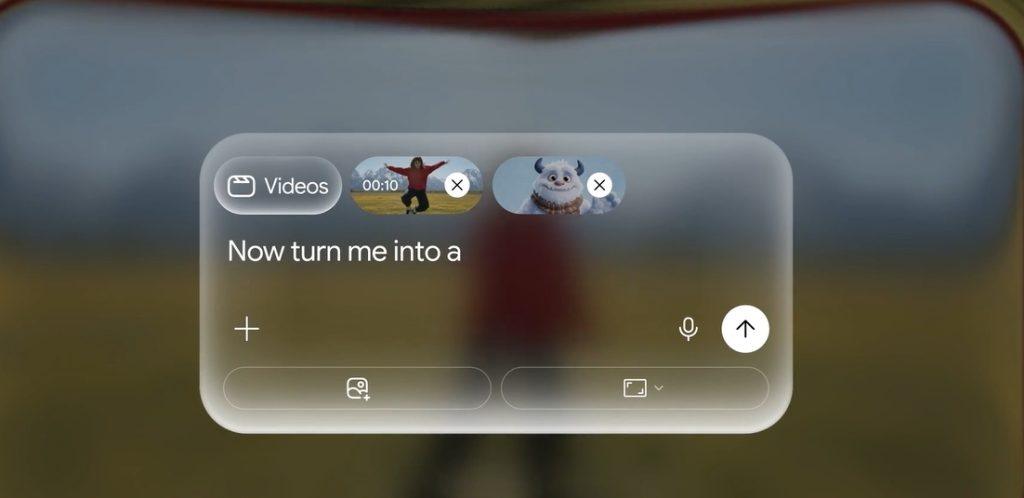
首先在操作流程上,以往不論是使用Runway、Sora或是Google自家的Veo 3.1,創作者都必須在提示詞(Prompt)裡精準猜測AI的解讀方式,一旦生成的畫面不滿意,就得重新撰寫整段文字重新碰運氣。
然而,根據官方展示,Gemini Omni引入了對話式協作邏輯。操作是使用者可以先上傳一段手機隨手拍的影片作為起點(Base),接著直接在對話框裡輸入修改指令,例如「把畫面背景換成賽博朋克風」或是「在右側加入一個走動的行人」。
「AI履歷健檢」看見自己優勢:https://campaign.1111.com.tw/resume-review/
更多科技工作請上科技專區:https://techplus.1111.com.tw/
AI接收指令後,會在保留原影片主體與鏡頭軌蹟的前提下進行局部重繪,更重要的是,這種修改是可以累加的,使用者能像跟人類剪輯師溝通一樣,針對上一步生成的結果說「行人衣服換成紅色」、「鏡頭往上拉高一點」,AI能夠在連續對話中維持角色外觀與場景的一致性。
這就牽涉到Gemini Omni與傳統影片生成產品的技術差異,過去的Veo 3.1或市面上其他常見的擴散模型,核心邏輯大多是「靜態圖片或文字的動態延伸」,強項在於原生畫質與光影表現(例如Veo 3.1主打的4K畫質與原生音訊配對),但在理解複雜物理法則與跨模態脈絡時容易穿幫,常常出現畫面融化或不合邏輯的扭曲,這也就是大家常說的恐怖谷效應。
相較之下,Gemini Omni是從底層架構就支持文字、圖片、音訊、影片同時輸入的原生多模態模型,它的定位不是要取代Veo 3.1,而是作為超越Nano Banana的模型。
官方強調Omni在訓練時加入了大量物理引擎數據與Google的知識庫,因此它對重力、動能、流體動力學有更深的理解。例如在官方展示影片中,輸入「手觸摸鏡面」的指令後,Omni能精準模擬出鏡面像液體般泛起漣漪、同時手臂逐漸轉為鏡面反射材質。這種將物理模擬的能力,讓它能透過簡單的短提示詞,就生成出符合科學邏輯的知識型動態解說影片。
不過從目前的技術規格來看,這次釋出的輕量版Gemini Omni Flash依然有其局限性。雖然它允許使用者透過照片與聲音樣本打造擬真的「數位分身(Digital Avatar)」來做影片主角,但為了防止深偽技術(Deepfake)的濫用,Google目前在音訊輸出上僅支援語音參考(Voice references),而語音語速的編輯功能仍處於內部測試中。此外,所有生成的影片都會被強制嵌入SynthID數位浮水印,雖然保障了版權與真實性,但在高度客製化的商業影音,如何與傳統剪輯軟體整合,可能仍然是個問題。
目前Gemini Omni Flash已經對全球Google AI Plus、Pro與Ultra訂閱用戶開放,這禮拜也正陸續推播至YouTube Shorts與YouTube Create App。整體而言,從官方展示作品來看,擺脫了過去AI生成影片只能「碰運氣」問題,讓影片生成可連續微調,至於實際推送後的產出品質,是否真能如Google宣稱般完美,這點仍有待後續關注。
延伸閱讀:
參考資料:
Google’s Gemini Omni can generate ‘anything from any input,’ starting with video
![]()
—
本篇文章授權來源:科技島




